Tratamiento de Logs masivos


Antes de nada querría decir que siento el parón en las publicaciones, nuestro compañero Juan me suplió hace poco con un post más que interesante sobre la red Tor. Me gustaría decir que he estado liado haciendo cosas interesantes, pero no es el caso. Simplemente diré que intentaré que no se vuelva a repetir.
Para introducir el post de hoy me gustaría comentar por encima un pequeño proyecto que desarrollé en la empresa hace ya un poco de tiempo. Como sabéis mi lenguaje preferido es python, y no sólo porque le pusieran el nombre en homenaje a esos locos Monty Python, sino porque su claridad siempre me ha fascinado. Pues bien, cuando tuvimos problemas con uno de los proyectos que conforman el stack de la empresa necesitábamos discernir si el problema se debía a cuestiones de arquitectura o bien a un exceso de peticiones. La cuestión es que de métricas siempre hemos ido un poco escasos porque casi nunca hay tiempo en el día a día para desarrollar más a fondo la parte de Zabbix.
El caso es que el análisis de los logs de apache mediante scripts y comandos de consola a pelo se nos quedaba corto, necesitábamos algo más. Desempolvando mis conocimientos de python y el acceso a base de datos mediante un api cómodo como es SQLAlchemy, opté por parsear los ficheros de logs diarios e introducirlos en una tabla con los datos de cada petición a nuestro servidor web, así se pueden realizar búsquedas cómodas vía SQL o incluso con el mismo api de python. Long story short, como dicen los angloparlantes, o resumiendo, como decimos por aquí, la introducción de datos es costosa aunque luego el análisis es muy cómodo. Mejoré bastante la parte de la introducción de datos e incluso utilicé otra librería de python para hacer unos bonitos gráficos que demostraron mi teoría, las peticiones excesivas no eran el problema así que había que poner el foco en otro lado.
El tema se solucionó satisfactoriamente y yo adquirí un poco más de destreza con mi lenguaje favorito. Todo ese proceso se merecerá otro post a modo de conocimiento histórico ya que lo que vamos a contar hoy creo que es un paso más en este tipo de análisis. Tengo un par de ideas para desarrolar más el otro proyecto, pero no sé si merecerá la pena.
Volviendo a nuestros experimentos actuales, resulta que tenemos unos compañeros que están realizando un máster en big data, tema hípster ande los haiga, pero el caso es que siempre nos cuentan cosas interesantes, como por ejemplo el tratamiento de logs masivos. Parece ser que una práctica habitual suele ser montar un stack ELK (ElasticSearch, Logstash y Kibana), en elasticsearch se guardaría la información, con logstash procesamos los logs y lo mostraríamos y trataríamos todo con kibana. Básicamente es lo mismo que hacía yo pero de una forma más ágil.
Buscando información de cómo montar este stack he encontrado un montón de tutoriales pero todos se refieren a versiones concretas de los diferentes proyectos y, seamos sinceros, a la velocidad que van las cosas ahora y con tres componentes teniendo que trabajar juntos un tutorial al uso se queda un poco anticuado. Vamos a intentar mostrar dónde buscar la información necesaria para realizar una instalación satisfactoria aunque las versiones hayan cambiado y avanzaremos un paso más ya que lo intentaremos instalar en una Ubuntu Server 14.04 LTS y en una recientísima Ubuntu Server 16.04 LTS.
Los tres proyectos están alojados bajo el mismo paraguas en la web de Elastic. Por seguir el orden natural vamos a instalar el primer componente del stack, la base de datos no relacional elasticsearch. Nos dirigiremos al apartado de su web donde explican cómo añadir sus sources para distribuciones basadas en debian y seguiremos los pasos:
# wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
OK
Crearemos el archivo /etc/apt/sources.list.d/elasticsearch-2.x.list con el siguiente contenido:
deb https://packages.elastic.co/elasticsearch/2.x/debian stable main
Ahora simplemente actualizamos las sources e instalamos el paquete:
ubuntu-server-14.04 # apt-get update
ubuntu-server-14.04 # apt-get install elasticsearch
ubuntu-server-16.04 # apt update
ubuntu-server-16.04 # apt install elasticsearch
Como véis esta es de las pocas diferencias entre las versiones LTS, podemos usar el comando apt sin el sufijo get. Si os fijáis en la dirección web donde explican la instalación de este primer paquete veréis que aparece current como versión del paquete, así cuando actualicen el proyecto podréis instalar sin problemas la última revisión. Además es necesario que los tres proyectos estén sincronizados ya que si cualquiera de ellos se instala con una versión anterior no trabajarán bien juntos.
Por supuesto hay una diferencia más entre versiones, SysV y SystemD por ello para hacer que el servicio arranque por defecto cuando la máquina se inicie nos aconsejan realizar el siguiente paso:
ubuntu-server-14.04 # update-rc.d elasticsearch defaults 95 10
ubuntu-server-16.04 # systemctl daemon-reload
ubuntu-server-16.04 # systemctl enable elasticsearch.service
Si probáis a arrancar el servicio nos encontraremos con una desagradable sorpresa, no tenemos ejecutable de java, nada que no tenga remedio gracias a los chicos de Web UPD8. Nos crearemos el fichero /etc/apt/sources.list.d/webupd8team-java.list con las siguientes líneas:
deb http://ppa.launchpad.net/webupd8team/java/ubuntu trusty main
deb-src http://ppa.launchpad.net/webupd8team/java/ubuntu trusty main
Tened en cuenta que para la versión 16.04 deberéis cambiar trusty por xenial. Añadimos la clave pública del repositorio:
# apt-key adv --keyserver keyserver.ubuntu.com --recv-keys EEA14886
Este comando es igual para las dos distribuciones aunque seguro que habrá alguna forma de utilizar sólo apt, pero por ahora nos sirve el legacy. Actualizamos e instalamos:
ubuntu-server-14.04 # apt-get update
ubuntu-server-14.04 # apt-get install oracle-java8-installer oracle-java8-set-default
ubuntu-server-16.04 # apt update
ubuntu-server-16.04 # apt install oracle-java8-installer oracle-java8-set-default
El segundo paquete nos dejará correctamente configurado el entorno de ejecución de la máquina virtual java. Lo más rápido, si os lo podéis permitir, es reiniciar el servidor, así matamos dos pájaros de un tiro, comprobaremos si el entorno se ha configurado correctamente y si al volver tenemos el servicio elasticsearch funcionando:
ubuntu-server-14.04 # service elastichsearch status
ubuntu-server-16.04 # systemctl status elasticsearch
También se nos ha olvidado un paso importante, instalar un apache para ver los resultados una vez que esté montado todo. Este paso también es muy sencillo:
ubuntu-server-14.04 # apt-get install apache2
ubuntu-server-16.04 # apt install apache2
Luego veremos que los gráficos no son impresionantes, pero tengo pendiente otro tutorial para poder introducir logs antiguos de nuestros servidores principales y ahí si veremos cosas interesantes.
Siguiente paso en el stack ELK, logstash. En esta dirección tenemos las instrucciones de instalación vía repositorios. Como ya tenemos la key pública nos saltamos ese paso y vamos directamente a crear el archivo con las fuentes, /etc/apt/sources.list.d/logstash-2.3.list:
deb http://packages.elastic.co/logstash/2.3/debian stable main
Los pasos son iguales que los de antes pero cambiando el nombre del paquete por logstash. Aunque veáis stable en las sources, que se corresponde con una distribución debian no habrá problemas de instalación en nuestras ubuntus, tanto xenial como trusty. Para nuestra configuración simple añadiremos un archivo de configuración típico de apache, /etc/logstash/conf.d/apache.conf:
input {
file {
path => '/var/log/apache2/access.log'
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
output {
elasticsearch { hosts => ["localhost:9200"] }
}
Como véis la cosa no tiene mucho secreto, tenemos un fichero de lectura, que es el de la configuración por defecto de apache y un filtro para parsear las líneas del log. También debemos añadir el usuario logstash al grupo adm para que tenga acceso al fichero de log del apache.
# adduser logstash adm
Seguramente en un servidor en producción nos buscaríamos algún método más fino de autorización pero por ahora nos vale. Ya podemos activar el servicio y lanzarlo para comprobar que esté funcionando correctamente:
ubuntu-server-14.04 # update-rc.d defaults logstash
ubuntu-server-14.04 # service logstash start
ubuntu-server-14.04 # service logstash status
ubuntu-server-16.04 # systemctl enable logstash
ubuntu-server-16.04 # systemctl start logstash
ubuntu-server-16.04 # systemctl status logstash
Debemos mover el log para que las máquinas se pongan en marcha:
$ for x in {1..10} ; do curl -s localhost ; done
Esto lo haremos en la máquina en la que estamos configurándolo todo, así tendremos datos alimentando logstash, para verificarlo podemos ejecutar el siguiente comando para ver que realmente tenemos un índice para ese archivo de logs:
$ curl localhost:9200/_aliases?pretty
{
"logstash-YYYY.MM.DD" : {
"aliases" : { }
}
}
Vamos con la joya de la corona, por lo menos es lo más llamativo del tema. Kibana nos mostrará toda esta información ordenada y además nos permitirá realizar búsquedas desde su interfaz web. El método es similar, por no decir igual, al de las otras dos piezas del puzzle. En esta dirección tenemos las instrucciones. Primero crearemos el fichero con las fuentes, /etc/apt/sources.list.d/kibana.list:
deb http://packages.elastic.co/kibana/4.5/debian stable main
Ahora simplemente instalamos el paquete y lo activamos para futuros reinicios del sistema:
ubuntu-server-14.04 # apt-get update
ubuntu-server-14.04 # apt-get install kibana
ubuntu-server-14.04 # update-rc.d defaults kibana
ubuntu-server-14.04 # service kibana start
ubuntu-server-14.04 # service kibana status
ubuntu-server-16.04 # apt update
ubuntu-server-16.04 # apt install kibana
ubuntu-server-16.04 # systemctl enable kibana
ubuntu-server-16.04 # systemctl start kibana
ubuntu-server-16.04 # systemctl status kibana
Si la salida del servicio es correcta podremos dirigirnos a nuestro navegador y accediendo a la ip del servidor pero apuntando al puerto 5601 podremos ver la interfaz web de kibana:
http://<ip_servidor>:5601
Aquí podéis ver la primera visualización:
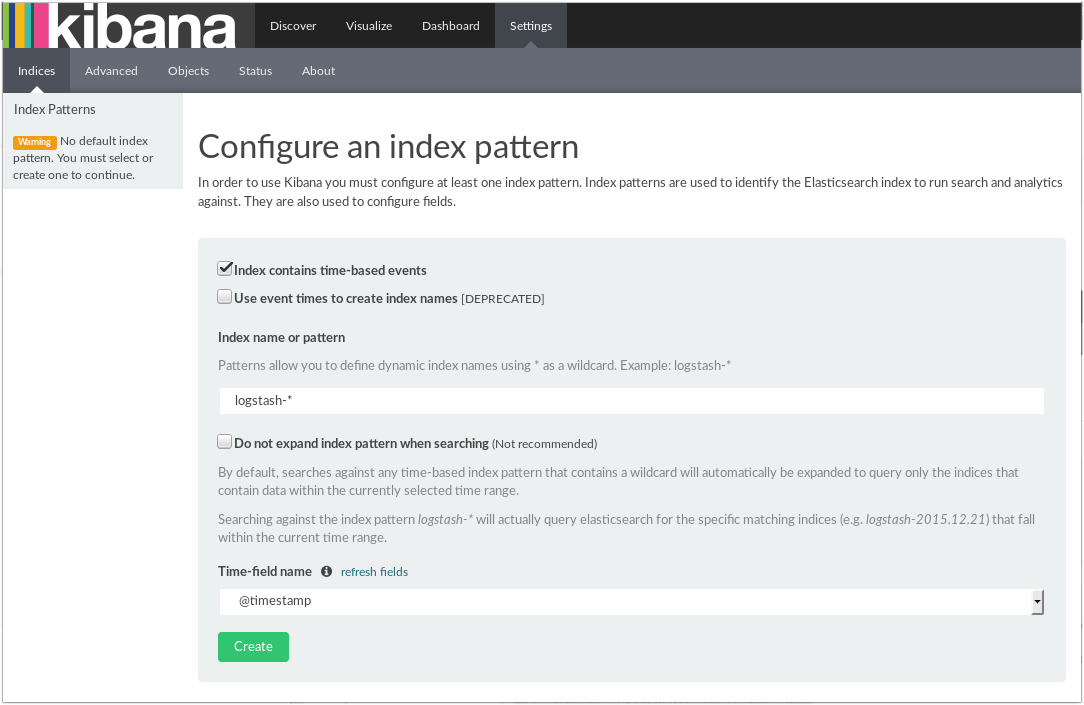
Como véis, parece que todo va viento en popa. Pinchando en el botón de crear accederemos a un mundo nuevo:
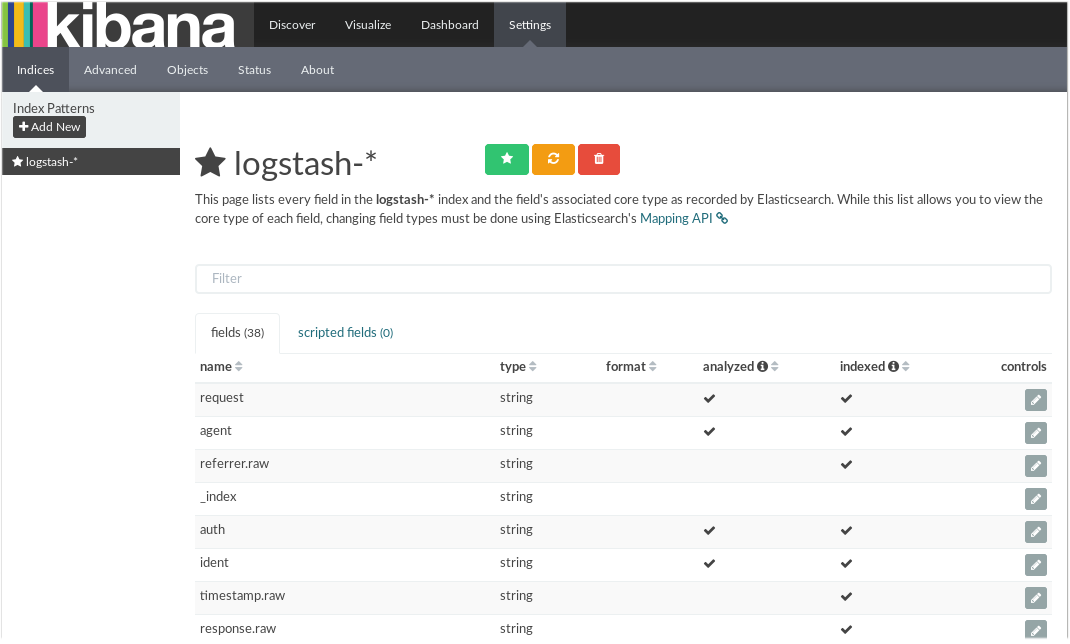
Aquí podemos ver los índices que se han creado por defecto, si queremos ver un poco de acción simplemente tendremos que acceder a la parte Discover y realizar unos cuantos accesos al servidor web:
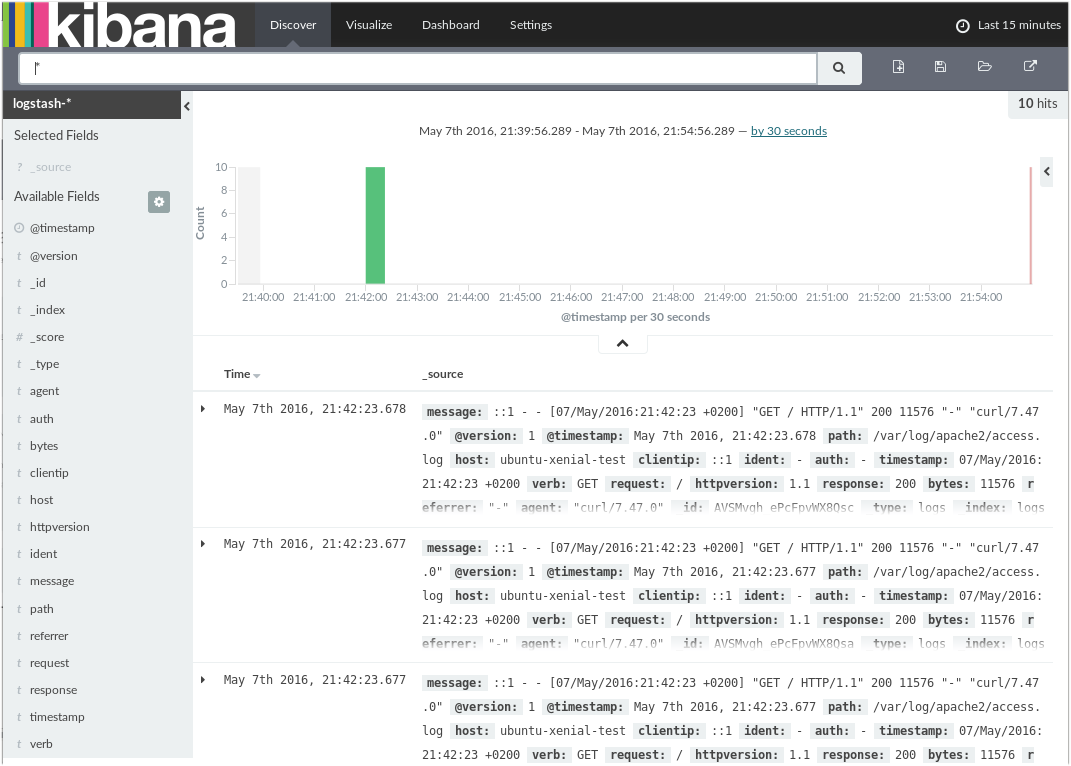
Si observáis la esquina superior derecha veréis un filtro de tiempo, si habéis tardado mucho entre los pasos descritos seguro que no véis ningún resultado, abriendo el marco de tiempo observaréis los primeros accesos que hemos hecho por línea de comandos al configurar el servicio logstash.
A partir de aquí ya podéis empezar a juguetear con los filtros, las visualizaciones y demás herramientas que nos brindan estas herramientas.
Por hacer me quedan unas cuantas cosas, la más importante es poder procesar los logs antiguos con sus marcas de tiempo originales ya que lo primero que pensé es volcar los archivos de logs mediante una tubería al archivo actual, pero resulta que el timestamp sería el del momento en que se introducen y no el que grabó el apache originalmente. Espero resolver esto en un próximo post, pero para empezar a guardar logs ya tenéis el stack preparado. También me queda hacerme un poco con la interfaz de kibana, que sé de buena tinta que se le puede sacar mucho jugo.
También hay que establecer un protocolo de actualizaciones ya que estos proyectos llevan un ritmo alto de desarrolloo y liberación de versiones y en cualquier actualización ordinaria del sistema se nos puede colar una versión nueva de cualquiera de los componentes y desmontarnos todo el tinglado. Baste decir que de los plugins de logstash, durante mi investigación, me he encontrado tres versiones diferentes para acceder a los archivos de logs. Lo mejor, en cualquier caso es acceder a la documentación original del proyecto en concreto para salir de dudas.
Creo que no me queda nada más que contar, reiterar mis disculpas por la tardanza en escribir, espero que el ritmo se recupere.
Para la canción de hoy podría haber elegido cualquiera de Muse ya que el concierto del otro día me encantó, como el resto de veces que los he visto, pero como este año es el primero al que faltamos al SOS4.8 y los Manic Street Preachers venían, voy a desempolvar de su disco This Is My Truth Tell Me Yours, el pedazo temazo If You Tolerate This Then Your Children Will Be Next que me trae grandes recuerdos de aquel 1995 cuando ya empezábamos a querer ir a todos los conciertos que se nos pusieran a tiro.